




誤差論と最小二乗法
第9回付録 線形(線型)代数の基礎3
2020年06月10日
A3.行列の演算2
行列の固有値と固有ベクトル
![]() 行列
行列![]() に対して
に対して
![]()
となるとき、![]() を
を![]() の固有値、
の固有値、![]() を
を![]() に属する固有ベクトルといいます。
に属する固有ベクトルといいます。
(1)が成り立つことは、![]() となる
となる![]() があることなので、
があることなので、![]() の列ベクトルは一次従属となり、
の列ベクトルは一次従属となり、![]() は正則ではありません。したがって、その行列式は0、つまり
は正則ではありません。したがって、その行列式は0、つまり
![]()
となります。
![]() を固有多項式といい、
を固有多項式といい、![]() に関して
に関して![]() 次の多項式です。 固有値は方程式(2)の根です。また、
次の多項式です。 固有値は方程式(2)の根です。また、![]() を
を![]() に属する固有ベクトルとすれば、
に属する固有ベクトルとすれば、
![]()
となるので、固有ベクトルはスカラー倍してもよいことがわかります。
対称行列![]() に関して次が成り立ちます。
に関して次が成り立ちます。
a. ![]() の固有値
の固有値![]() は実数。
は実数。
b. 異なる固有値に属する固有ベクトルは、互いに直交する。同じ固有値に属する固有ベクトルは、
互いに直交するように選ぶことができる。
ベクトルの正規化
ベクトル![]() の長さは
の長さは![]() ですが、
ですが、
![]()
は、![]() と同じ向きを持つ長さ1のベクトルです。これをベクトルの正規化といいます。
と同じ向きを持つ長さ1のベクトルです。これをベクトルの正規化といいます。
直交行列
![]() 行列
行列 ![]() の列が、互いに直交し正規化されているとき、直交行列といいます。
の列が、互いに直交し正規化されているとき、直交行列といいます。
直交行列 ![]() には、次の性質があります。
には、次の性質があります。
![]()
これは、![]() を列ベクトルで
を列ベクトルで
![]()
と書くと、![]() の
の![]() 成分が
成分が
![]()
となることからわかります(第7回付録参照)。また、ベクトル![]() に直交行列
に直交行列![]() を掛けて
を掛けて
![]()
に変換すると、
![]()
より、変換されたベクトルの長さは不変なので、直交行列による変換は回転になることがわかります。
対称行列の対角化
対称行列![]() に対して、直交行列
に対して、直交行列![]() が存在して、
が存在して、
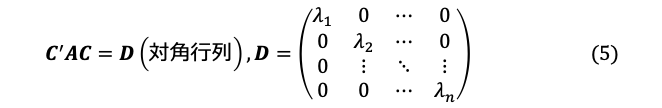
となります。ここで、![]() は
は![]() の固有値、
の固有値、![]() の列ベクトル
の列ベクトル![]() は、固有値
は、固有値![]() に属する正規化された固有ベクトルです。
に属する正規化された固有ベクトルです。
また、(5)を変形すれば
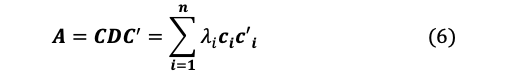
となります(スペクトル分解)。
B2. 仮説検定と区間推定
1.仮説検定
検定と有意性
検定(仮説検定)は、統計学において推定と並ぶ二つの柱の一つです。検定とは、母集団についての仮説をデータにもとづいて検証することです。観測結果が理論から期待される値と厳密に一致することはありませんが、その差が誤差の範囲なのか、それ以上に何か意味のあるものかを調べることになります。何か意味のあることを「有意」といい、仮説が有意か否かによって、仮説を棄却するか、あるいはしないかを決定することになります。有意の基準は確率で示され有意水準といい、 α で表すことが普通です。例えば α = 0.1( 10% ) とし、データが得られた確率が仮説に基づいて計算したところ 0.05( 5% ) となった場合、その仮説は棄却されます。
帰無仮説と対立仮説
仮説検定を確率分布とその母数(パラメータ)から見てみると、検定とは母数に関する仮説が正しいかをデータから決めることです。パラメータ θ の全体集合を Θ とすると、仮説 H0 とは、 θ が Θ の部分集合 Θ0 にふくまれること、 H0 : θ ∈ Θ0 と定義されます。H0 と対立する仮説 H1 ( H1 : θ ∉ Θ0 ) を立てることもあり、H0 を棄却するということは、H1 を採択することになります。 H0 を帰無仮説、 H1 を対立仮説といいます。帰無とは、最初に立てた仮説が無に帰る=棄却される、という意味で、否定されることを期待することが多いので統計学ではそのような名前が付けられています。単に「仮説」として考えても問題ありません。
片側検定と両側検定
仮説検定の例として、平均値に関する検定を考えます。
ある量(長さ、温度、成分などn=10を回測って、
![]()
得たとします。母集団を
![]()
とし、このデータから μ = 18.0 であることを有意水準 α=0.05 で検定したいと思います。
帰無仮説は H0 : μ = 18.0
対立仮説は H1 : μ ≠ 18.0
です。
ここでは、母集団の分散が未知なので、次の統計量が従う自由度 n – 1 の t 分布( 第5回 )を利用した t 検定を行います。
![]()
t 分布は、図1のようになり、 ![]() の値が
の値が![]() より小さいか、または
より小さいか、または![]() より大きい確率はαとなります。
より大きい確率はαとなります。![]() を α/2 パーセント点といいます(一般には小さいほうのパーセント点は
を α/2 パーセント点といいます(一般には小さいほうのパーセント点は![]() ですが、 t 分布は 0 を中心に左右対称なので、
ですが、 t 分布は 0 を中心に左右対称なので、![]() です。)
です。)
従って、
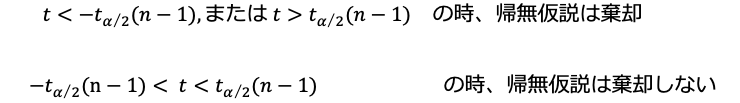
となり、仮説が棄却される値の領域を棄却域、棄却しない領域を採用域といいます。図1では、棄却域は両端の影がついた部分、採用域は中間部分です。
この例では、t = -0.90 となり、α = 0.05 に対する α/2 パーセント点は![]() ですから、仮説は棄却しないことになります。また、棄却域は分布の両側にあるので両側検定といいます。
ですから、仮説は棄却しないことになります。また、棄却域は分布の両側にあるので両側検定といいます。
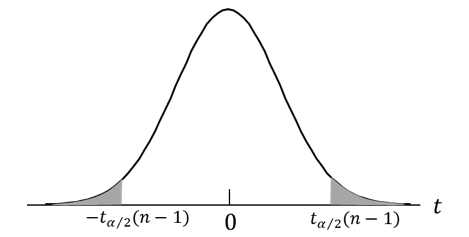
図1.両側検定
もし対立仮説が、H1 : μ < 18.01 ならば、平均値が非常に小さくなった時にのみ帰無仮説を棄却することになるので α パーセント点は![]() となり、-1.83 < -0.90 なので帰無仮説は棄却されません。棄却域は
となり、-1.83 < -0.90 なので帰無仮説は棄却されません。棄却域は![]() となり片側検定といいます。また、対立仮説の不等号を逆にすれば、棄却域は
となり片側検定といいます。また、対立仮説の不等号を逆にすれば、棄却域は![]() となり、これも片側検定です。(図2)。
となり、これも片側検定です。(図2)。
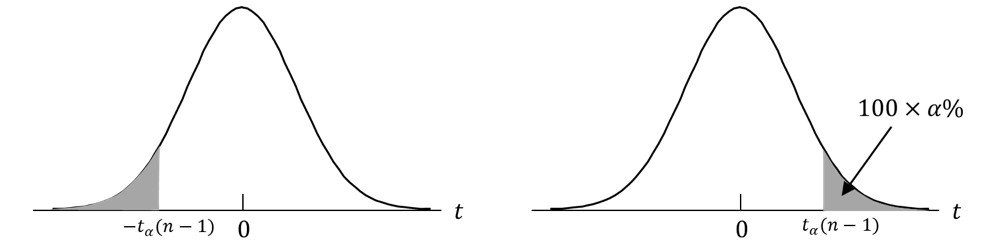
図2.左片側検定と右片側検定
母分散に関する検定
次の例として、母集団の分散![]() に関する検定を考えます。連載5回によると
に関する検定を考えます。連載5回によると
![]()
は自由度 n – 1 の![]() 分布に従うことがわかっています。平均値の検定と同じように、帰無仮説を、
分布に従うことがわかっています。平均値の検定と同じように、帰無仮説を、![]() とし、有意水準で以下の対立仮説に応じて検定を行います。
とし、有意水準で以下の対立仮説に応じて検定を行います。
1) ![]() なら両側検定で、
なら両側検定で、![]() なら H0 は棄却せず、それ以外は棄却。
なら H0 は棄却せず、それ以外は棄却。
2) ![]() なら左片側検定で、
なら左片側検定で、![]() なら H0 を棄却、それ以外は棄却しない。
なら H0 を棄却、それ以外は棄却しない。
3) ![]() なら右片側検定で、
なら右片側検定で、![]() なら H0 を棄却、それ以外は棄却しない。
なら H0 を棄却、それ以外は棄却しない。
これらを正規母集団の母分散に関する![]() 検定といいます(図3)。
検定といいます(図3)。


図3.![]() 検定、両側(上)と片側検定
検定、両側(上)と片側検定
F分布と分散の比に関する検定
二つの確率変数 u と v が独立で、それぞれ![]() と
と![]() に従うとき、その比
に従うとき、その比![]() が従う確率分布を自由度( m, n ) のF分布 F(m,n) といいます(図4)。
が従う確率分布を自由度( m, n ) のF分布 F(m,n) といいます(図4)。

図4.F分布
F分布は二つの正規母集団の分散について調べるときに使われます。二つの集団から得られた標本分散を、![]() とすると(8)より、
とすると(8)より、
![]()
ですから、
![]()
となり、F検定を行うことができます。
2.区間推定
(点)推定は、未知パラメータ θ を一つの値として推定するものですが、区間推定は θが含まれるであろう区間(領域)をデータyによって推定するものです。式で書くと、θ が含まれる確率が 1 – α であるような区間、つまり
![]()
となる ( l( y ), u( y ) ) を求めることです。区間 ( l( y ), u( y ) ) を 100( 1 – α )% 信頼区間、l( y ), u( y ) を信頼限界といいます。1 – α は多くの場合、0.99 や 0.95 に選ばれます。信頼区間は、![]() の標本分布から決められます。
の標本分布から決められます。
信頼区間の意味
信頼区間はあるデータから計算され、データが違えばその値も変動します。パラメータの(真の)値は常数ですから、それが計算された信頼区間にある確率で含まれるということはありません。信頼区間が意味することは、同じ観測を何回も繰り返して信頼区間を計算したとき、θ を区間内に含む観測の割合が 1 – α であるということです。
正規母平均の区間推定
母集団の分散が未知のとき、(7)は t 分布に従いますから、
![]()
これをμについて解くと、
![]()
となり、μの 1 – α 信頼区間は
![]()
です。
両側検定の例で使った結果の95パーセント信頼区間を求めてみましょう。
n=10、平均値![]() = 17.86、標本分散
= 17.86、標本分散![]() = 0.243、
= 0.243、![]() = 2.26 でしたから、95パーセント信頼区間は、
= 2.26 でしたから、95パーセント信頼区間は、
![]()
より、 ( 17.51, 18.21 ) となります。
B3. 正規分布の性質
(多次元)正規分布をする確率変数の性質をまとめておきます。
確率変数の独立性
正規分布をしている確率変数ベクトル![]() を
を![]() のようにいくつかに分けたとき、対応する共分散行列も以下のように
のようにいくつかに分けたとき、対応する共分散行列も以下のように![]() とブロックに分けられますが、
とブロックに分けられますが、
![]()
![]() ならば、
ならば、![]() はおのおの独立になります(逆も真)。
はおのおの独立になります(逆も真)。
確率変数の線形関数
( n × 1 ) ベクトル![]() が正規分布をしているとき
が正規分布をしているとき![]()
![]() から線形変換で得られた ( m × 1 ) ベクトル
から線形変換で得られた ( m × 1 ) ベクトル
![]()
は、A のランクが m ならば正規分布に従います。
![]()
例.最小二乗解の誤差分布
最小二乗解
![]()
は、データ![]() の線形変換
の線形変換![]() のランクは
のランクは ![]() ですから、
ですから、![]() が正規分布、
が正規分布、
![]()
ならば、![]() も正規分布で
も正規分布で![]() より
より
![]()
となります。
確率変数の和
( n × 1 ) ベクトル![]() が独立で、正規分布
が独立で、正規分布![]() に従うとき
に従うとき
( n × 1 ) ベクトル![]() も正規分布となります。
も正規分布となります。
![]()
ここで、![]() です。
です。
参考文献
1. Koch, K-R., Parameter Estimation and Hypothesis Testing in Linear Models, Springer, 1999.






